
最近刷题,复习Java常用类是突然想起来以前做过的比较,不甚成熟,补充在一起。
作业1
Java,Python和JavaScript中对事件机制的支持语法及使用方法
在c#中
事件在类中声明且生成,且通过使用同一个类或其他类中的委托与事件处理程序关联。
包含事件的类用于发布事件。这被称为 发布器(publisher) 类。其他接受该事件的类被称为 订阅器(subscriber) 类。事件使用 发布-订阅(publisher-subscriber) 模型。
发布器(publisher) 是一个包含事件和委托定义的对象。事件和委托之间的联系也定义在这个对象中。发布器(publisher)类的对象调用这个事件,并通知其他的对象。
订阅器(subscriber) 是一个接受事件并提供事件处理程序的对象。在发布器(publisher)类中的委托调用订阅器(subscriber)类中的方法(事件处理程序)。
观察者模式是一种常用的设计模式,这种设计模式刚好可以用于事件驱动机制。
Python中的事件机制
参考自博客(https://blog.csdn.net/brucewong0516/article/details/84031715)
监听器(subscriber)监听了事件源(publisher),当事件源发送事件时,所有监听该事件的监听器(subscriber)都会接收到消息并作出响应。
Python中也有event(事件),是线程threading模块中的一个类,它提供了简单的几个方法,set(), clear(), wait(timeout), isSet()。而我们要探讨的事件机制是以下的实现方法。
已知Python中可直接传递函数名,实现类似c#中委托的功能,故可以在注册事件的回调时,代入一个参数callback,在注册函数实体内,存在一个list将callback添加进去,
1 | def register_callback(self, cb): |
以下是一个稍显复杂的实现方法。通过eventManager可以实现事件触发,当事件触发时,推送事件到线程中运行。eventManager主要包含以下几个方法。
run(), AddEventListener(), RemoveEventListener(), SendEvent()
1 | from queue import Queue, Empty |
实例调用
1 | import sys |
Java的事件机制
参考自博客(https://www.jianshu.com/p/ccd468c6be8a) (https://www.cnblogs.com/liao13160678112/p/6596218.htm) (https://www.cnblogs.com/yulinfeng/p/5874015.html)
用观察者模式实现事件机制
对于观察者模式,Java已经为我们提供了已有的接口和类。可以利用Java提供的Observer接口和Observable类实现观察者模式。
1 | import java.util.Observable; |
也可以自己实现。
1 | public class Event { |
观察者模式存在不足之处,两个观察者模式的观察者都是实现了同一接口,如果两个观察者风马牛不相及又该怎么办。参考委托和事件的关系,我们可以用callback实现一个“委托”,即也可以用反射实现事件机制。
1 | /*事件处理类*/ |
JavaScript的事件机制
参考自博客(https://blog.csdn.net/a2013126370/article/details/82290180)
事件是将JavaScript和网页联系在一起的主要方式。
事件:用户或浏览器自身执行的某种动作,换言之,文档或浏览器发生的一些特定的交互瞬间。
事件处理程序:又称事件侦听器,事件发生时执行的代码段。
事件流:事件流描述的是从页面中接收事件的顺序。
两种基本事件模型
事件冒泡:事件按照从最特定的事件目标到最不特定的事件目标(document对象)的顺序触发。
事件捕获:事件从最不精确的对象(document 对象)开始触发,然后到最精确。
DOM事件流
同时支持 两种基本事件模型,规定事件流包括三个阶段:事件捕获阶段、处于目标阶段、事件冒泡阶段。
DOM事件处理程序绑定时,程序员可以自己选择绑定事件时采用事件捕获还是事件冒泡。
IE事件流
IE只支持事件冒泡,不支持事件捕获。
事件处理程序绑定方式
DOM事件处理方式,可以通过addEventListener方法
addEventListener(“事件名”,事件处理程序,ture/false:在事件捕获/冒泡阶段调用模型)
对应的事件处理程序移除方法:removeEventListener,参数必须相同。
IE事件处理程序
程序作用域为全局作用域,this指向window对象
添加方法:attachEvent(“on+事件名”,事件处理程序)
移除方法:detachEvent(“on+事件名”,事件处理程序)
综合以上所述,写可跨浏览器的事件处理程序(构造EventUtil对象,为其添加可兼容各浏览器的事件处理方法),如下:
1 | /*可跨浏览器的事件处理程序 |
作业2
简介Java和Python中对常用数据容器的支持库和使用方式
Java的常用库
参考自菜鸟教程,Java官方中文文档
Java提供的数据集合主要涉及两部分,一部分是java.util.Collection的实现类,一部分是java.util.Map的实现类。
Java框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
因为相关类众多,这里做一个简单的示例。使用Java提供的类库是要使用import, 注意Java对大小写敏感。
import java.util.*;
Collection接口
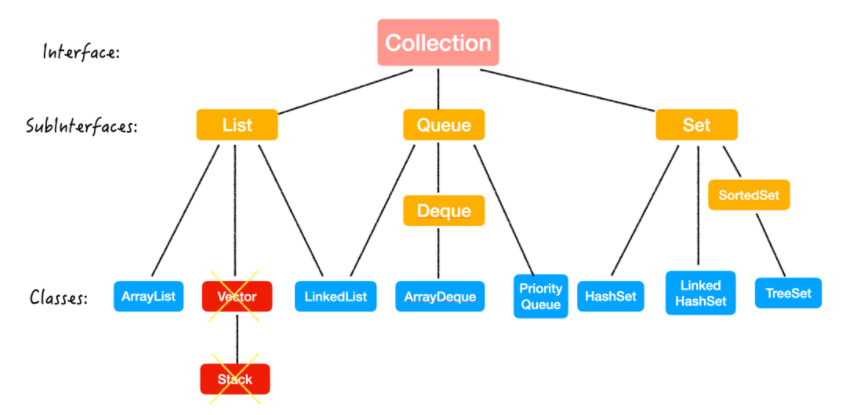
List接口是有序的collection。List最大的特点就是有序可重复。Set正与List相反,无序不可重复。
List的子类,有Vector,ArrayList,LinkedList。
1) ArrayList, 是基于数组实现的List类,它封装了一个动态的增长的,允许再分配的Object[]数组,允许对元素进行快速随机访问。
1 | import java.util.ArrayList; |
2)Vector,是通过数组实现的,不同的是它支持线程的同步。
1 | import java.util.Vector; |
3)Stack,是Vector提供的一个子类,模拟栈的数据结构。
1 | import java.util.Stack |
Vector已经建议弃用了,因为它加了太多的synchronized。Stack继承了Vector也弃用了
Vector和ArrayList的区别是什么
一是线程安全问题,二是扩容问题,Vector默认扩容两倍,而ArrayList扩容实现用的算术右移,新容量是原来的1.5倍
4)LinkedList是用链表结构存储数据的,很适合数据的动态插入和删除。
1 | import java.util.LinkedList; |
List的实现方式有LinkedList和ArrayList两种,如何选择,要考虑到实现的功能和效率问题。链表和数组的最大区别就是数组是可以随机访问的。这部分的效率问题其实就是数据结构的内容。
Set接口
Set接口的实现类有HashSet,TreeSet,LinkedHashSet。
1) HashSet类,用Hash算法来存储集合中的元素。
1 | import java.util.HashSet; |
2)LinkedHashSet,也是根据元素的hashCode值来决定元素的存储位置,但和HashSet不同的是,它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。
3)EnumSet是一个专门为枚举类设计的集合类,EnumSet中所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式、或隐式地指定。EnumSet的集合元素也是有序的
4)TreeSet采用红黑树结构,特点是可以有序。
Queue接口
Queue有两组API,基本功能是一样的。根据需求选择一组统一使用。
1) 提供了Deque接口,专门用于操作表头和表尾,可以当作堆栈,队列和双向队列使用。
2) PriorityQueue,优先队列按照队列中某个属性的大小来排列。
在实现普通队列时建议使用ArrayDeque,效率更高。只要不是不需要存null值,就用ArrayDeque。
Map接口
用于保存具有映射关系的数据。
Map的子类,子接口
1)HashMap和HashSet集合不能保证元素的顺序一样,HashMap也不能保证key-value对的顺序。并且类似于HashSet判断两个key是否相等的标准一样: 两个key通过equals()方法比较返回true、 同时两个key的hashCode值也必须相等
1 | import java.util.HashMap; |
2)HashTable类是一个古老的Map实现类。
3)SortedMap接口下的类,TreeMap类,是一个红黑树结构,每个键值对都作为红黑树的一个节点。TreeMap存储键值对时,需要根据key对节点进行排序,TreeMap可以保证所有的key-value对处于有序状态。 同时,TreeMap也有两种排序方式:自然排序、定制排序(类似于上面List的重写CompareTo()方法)。
Python的常用库
参考自菜鸟教程, python中文手册
Python中同样提供了一些基本容器,列表,元组,字典和集合,以及collections中几种已经预先实现的容器数据结构namedtuple(), deque, ChainMap, Counter, OderedDict, defaultdict等等
同样的Python的每一数据类型都包含了很多的方法。以list为例:
1 | list.append(x) |
具体的使用说明可参考官方文档。
Python数据类型
首先,Python中的基本顺序存储结构是列表和元组,在操作和复杂度上和数组完全相同,其中列表是可变数据类型,元组是不可变数据类型。
1)list是Python中最基本的数据结构,列表的数据项不需要具有相同的数据类型。
1 | list = ['red', 'green', 12] |
list也可以当作堆栈和队列来用。
2)元组与列表类似,不同之处在于元组的元素不能修改。
1 | tup1 = ('physics', 'chemistry', 1997, 2000) |
3)字典是另一种可变容器模型,可存储任意类型对象
1 | dict = {'a': 1, 'b': 2} |
4)集合set是一个无序的不重复元素序列。基本功能包括关系测试和消除重复元素。集合对象还支持 union(联合),intersection(交),difference(差)和 sysmmetric difference(对称差集)等数学运算。
1 | thisset = set(("google", "runoob", "taobao")) |
collections模块
Python的collections模块实现了一些数据结构,使用时可以用import导入
import collections
栈和队列
1)namedtuple是继承自tuple的子类,namedtuple创建一个和tuple类似的对象,而且对象拥有可访问的属性。
1 | from collections import namedtuple |
2)队列
1 | import queue |
3)双端队列
1 | from collections import deque |
作业3
编写有序表合并算法代码,以及相应的单元测试代码
1 | namespace demo |
测试代码
1 | using System; |